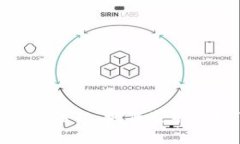
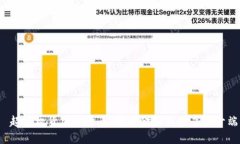
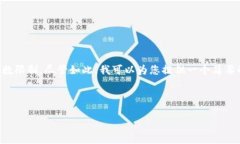
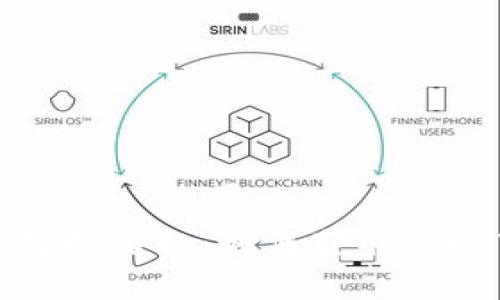
引言 随着加密货币的崛起,许多领域开始探索如何将数字货币与各自的行业结合起来。发型行业也不例外。用户对于...
加密货币数据爬取是一项技术工作,通过编程手段从网络上的加密货币交易平台或者信息网站上获取有关加密货币的信息。这些数据可以包括价格变化、交易量、用户信息等,帮助用户及时掌握市场动态。
数据爬取通常使用爬虫技术,编写特定的代码来访问网络资源,模拟人工浏览器进行操作,从而提取出需要的信息。Python是目前数据爬虫领域使用最广泛的语言之一,因其丰富的库和强大的数据处理能力,成为数据科学家的热门选择。
###
加密货币数据爬取的基本步骤主要包括:
1. **选择目标网站**:在确定需要爬取的加密货币数据之前,首先要选择数据来源,如CoinMarketCap、Binance、CoinGecko等。 2. **分析网页结构**:通过开发者工具,查看网站的HTML结构,以确定所需数据的具体位置。 3. **编写爬虫程序**:使用如Python中的`requests`和`BeautifulSoup`库,或者`Scrapy`框架编写爬虫,直接获取所需的数据。 4. **数据存储**:获取到的数据可以存储在本地文件、数据库或云存储中,以便后续分析。 5. **数据分析**:完成数据爬取后,可以使用数据分析工具如Pandas、Matplotlib等对数据进行处理和可视化,获取有价值的洞见。 ###在进行加密货币数据爬取时,程序员们通常会使用一些开源库和工具,以下是一些热门选择:
- **Requests**:一个强大的HTTP库,用于发送网络请求,获取网页数据。 - **BeautifulSoup**:用于解析和提取HTML和XML文档信息的库。 - **Scrapy**:一个框架,用于快速构建爬虫程序,能够实现复杂的数据抓取和处理。 - **Selenium**:用于自动化测试及抓取动态网页内容的工具,适合处理JavaScript生成内容的网站。 ### 在爬取过程中的确可能会遇到一些问题,以下是一些常见问题及其解决方案:
####
在爬取过程中的确可能会遇到一些问题,以下是一些常见问题及其解决方案:
#### 许多网站会设置反爬虫机制,限制自动程序的访问。例如,限制IP访问频率,甚至通过Captcha验证来阻止爬虫。
解决反爬虫问题的方法包括:使用代理IP池、设置请求头伪装成浏览器请求、合理设置爬取频率、增加随机时间间隔等。此外,可以采用分布式爬虫,利用多台服务器同时进行数据抓取。
####在数据爬取中,东拼西凑的数据来源以及数据格式不规范都会影响数据的准确性。决定一个数据源的准确性需要验证其历史数据与市场行情是否一致。
获取数据的准确性可以通过多种方式验证,例如交叉比对数据来源,检查数据的时间戳确保时效性,使用数据清洗技术来规整数据格式等。
####爬取的数据可以存储于多种形式,多数人会选择使用CSV文件或数据库。这需要根据所需的数据规模和分析方式来决定。
对于小规模数据,CSV文件是一个便捷的选择。而对于大规模数据,使用关系型数据库(如MySQL、PostgreSQL)或者NoSQL(如MongoDB)能更好地管理和查询。
####数据分析和可视化可以帮助用户更好地理解数据,得出市场趋势。常用的数据分析库包括Pandas和NumPy,而可视化工具一般采用Matplotlib和Seaborn。
数据分析的过程大致包括数据的统计描述、数据的相关性分析,以及建立预测模型等过程。可视化则可以通过折线图、柱状图等形式展示数据变化。
####加密货币市场变化迅速,如何获取实时数据是个棘手问题。实时数据通常可以通过API接口访问获取。
针对实时更新,建议使用WebSocket协议进行实时通信,能够在数据发生变化时即时接收更新数据。此外,定时抓取更新入口也可以是一个可行的方案,确保在数据变化时可以及时更新。
###加密货币市场的庞大和复杂,为用户提供了极大的数据需求。数据爬取技术的运用,让获取数据变得更加高效和准确。无论是个人投资者、研究者还是行业分析师,都会从中受益。
通过本文的介绍,读者可以掌握加密货币数据爬取的基本理论与实践技巧,同时也能系统了解数据爬取过程中的常见挑战及应对方案。希望更多的用户能够利用这些数据,进行深入的市场分析,做出更加明智的决策。


引言 随着加密货币的崛起,许多领域开始探索如何将数字货币与各自的行业结合起来。发型行业也不例外。用户对于...
在过去的十年中,加密货币市场经历了翻天覆地的变化,各种数字资产层出不穷。这一市场的迅速发展吸引了全球投...
加密货币的快速发展使得越来越多的人开始投入这一市场,同时对于如何查询和管理加密货币资产的需求也随之上升...

什么是加密货币硬顶? 加密货币硬顶是指一种规定在特定时期内,某种加密货币的最高供应量限制。这种设计旨在防...